Managing Output Data
Once a model is created and successfully run, it will hopefully produce results and output data. This section covers how the writing of output data is controlled and managed.
Specifying Your Output Data Store
In your workflow (for more details see Setting up a workflow for SpineOpt in Spine Toolbox) you will normally have a output datastore connected to your RunSpineOpt workflow tool. This is where your output data will be written. If no output datastore is specified, the results will be written by default to the input datastore. However, it is generally preferable to define a separate output data store for results. See Setting up a workflow for SpineOpt in Spine Toolbox for the steps to add an output datastore to your workflow)
Specifying Outputs to Write
Outputting of results to the output datastore is controlled using the output and report object classes. To output a specific variable to the output datastore, we need to create an output object of the same name. For example, to output the unit_flow variable, we must create an output object named unit_flow. The SpineOpt template contains output objects for most problem variables and importing or re-importing the SpineOpt template will add these to your input datastore. So it is probable these output objects will exist already in your input datastore. Once the output objects exist in your model, they must then be added to a report object by creating an report__output relationship
Creating Reports
Reports are essentially a collection of outputs that can be written to an output datastore. Any number of report objects can be created. We add output items to a report by creating report__output relationships between the output objects we want included and the desired report object. Finally, to write a specic report to the output database, we must create a model__report relationship for each report object we want included in the output datastore.
Reporting of Input Parameters
In addition to writing results as outputs to a datastore, SpineOpt can also report input parameter data. To allow specific input parameters to be included in a report, they must be first added as output objects with a name corresponding exactly to the parameter name. For example, to allow the demand parameter to be included in a report, there must be a correspondingly named output object called demand. Similarly to outputs, to include an input parameter in a report, we must create a report__output relationship between the output object representing the input parameter (e.g. demand) and the desired report object.
Reporting of Dual Values
To report the dual of a constraint, one can add an output item with the corresponding constraint name (e.g. constraint_nodal_balance) and add that to a report. This will cause the corresponding constraint's marginal value to be reported in the output DB. When adding a constraint name as an output we need to preface the actual constraint name with constraint_ to avoid ambiguity with variable names (e.g. units_available). So to report the marginal value of units_available we add an output object called constraint_units_available.
To report the reduced_cost() for a variable which is the marginal value of the associated active bound or fix constraints on that variable, one can add an output object with the variable name prepended by bound_. So, to report the unitson reducedcost value, one would create an output item called bound_units_on. If added to a report, this will cause the reduced cost of unitson in the final fixed LP to be written to the output db. Finally, if any constraint duals or reducedcost values are requested via a report, calculate_duals is set to true and the final fixed LP solve is triggered.
Output Data Temporal Resolution
To control the resolution of report data (both output data and input data appearing in reports), we use the output_resolution output parameter. For the specific output (or input), this indicates the resolution at which the values should be reported. If output_resolution is null (the default), results are reported at the highest available resolution that will follow from the temporal structure of the model. If output_resolution is a duration value, then the average value is reported.
Output Data Structure
The structure of the output data will follow the structure of the input data with the inclusion of additional dimensions as described below:
- The report object to which the output data items belong will be added as a dimension
- The relevant stochastic scenario will be added as a dimension to all output data items. This allows for stochastic data to be written to the output datastore. However, in deterministic models, the single deterministic scenario will still appear as an additional dimension
- For unit flows, the flow direction is added as a dimension to the output.
Example: unit_flow
For example, consider the unit_flow) optimisation variable. This variable is dimensioned on the unit__to_node and unit__from_node relationships. In the output datastore, the report, stochastic_scenario and flow direction are added as additional dimensions. Therefore, unit__to_node values will appear in the output datastore as timeseries parameters associated with the report__unit__node__direction__stochastic_scenario relationship as shown below.
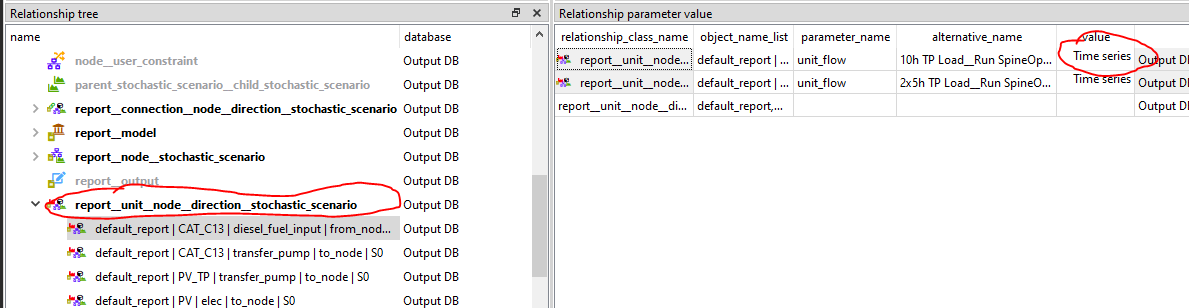
To view the data, simply double-click on the timeseries value
Example: units_on
Consider the units_on) optimisation variable. This variable is dimensioned on the unit object class. In the output datastore, the report and stochastic_scenario are added as additional dimensions. Therefore, units_on values will appear in the output datastore as timeseries parameters associated with the report__unit__stochastic_scenario relationship as shown below.

To view the data, simply double-click on the timeseries value
Alternatives and Multiple Model Runs
- All outputs from a single run of a model will be tagged with a unique "alternative". Alternatives allow multiple values to be specified for the same parameter. If a model is run multiple times, the results will be appended to the output datastore with a new alternative which uniquely identifies the scenario and model run. This is convenient as it allows results from multiple runs and for multiple scenarios to be viewed and compared simultaneously. If a specific altnernative is not selected (the default condition) the results for all alternatives will be visible. If a single altnerative is selected or multiple alternatives are selected in the altnerative tree, then only the results for the selected alternatives will be shown.
In the example below, the relationship class report__unit__stochastic_scenario is selected in the relationship treem therefore results for that relationship class are showing in the relationship parameter pane. Furthermore, in the alternative tree, the alternative 10h TP Load _Reun SpineOpt... is selected, meaning only results for that alternative are being displayed.

Output Writing Summary
- We need an output object in our intput datastore for each variable or marginal value we want included in a report
- Inputs data can also be reported. As above, we need to create an output object named after the input parameter we want reported
- We need to create a report object to contain our desired outputs (or input parameters) which are added to our report via report__output relationships
- We need to create a model__report object to write a specific report to the output datastore.
- The temporal resolution of outputs (which may also be input parameters) is controlled by the output_resolution output duration parameter. If
null, the highest available resolution is reported, otherwise the average is reported over the desired duration. - Additional dimensions are added to the output data such as the report object, stochastic_scenario and, in the case of unit_flow, the flow direction.
- Model outputs are tagged with altnernatives that are unique to the model run and scenario that generated them